自定义知识图谱
计算性云平台支持自定义知识图谱管理,增强用户的资料、文档、知识的检索能力。
开始
在定制数据管理卡片,点击自定义知识图谱,进入知识库管理模块。此模块中允许用户创建知识库,根据需要进行知识图谱构建。
创建知识库
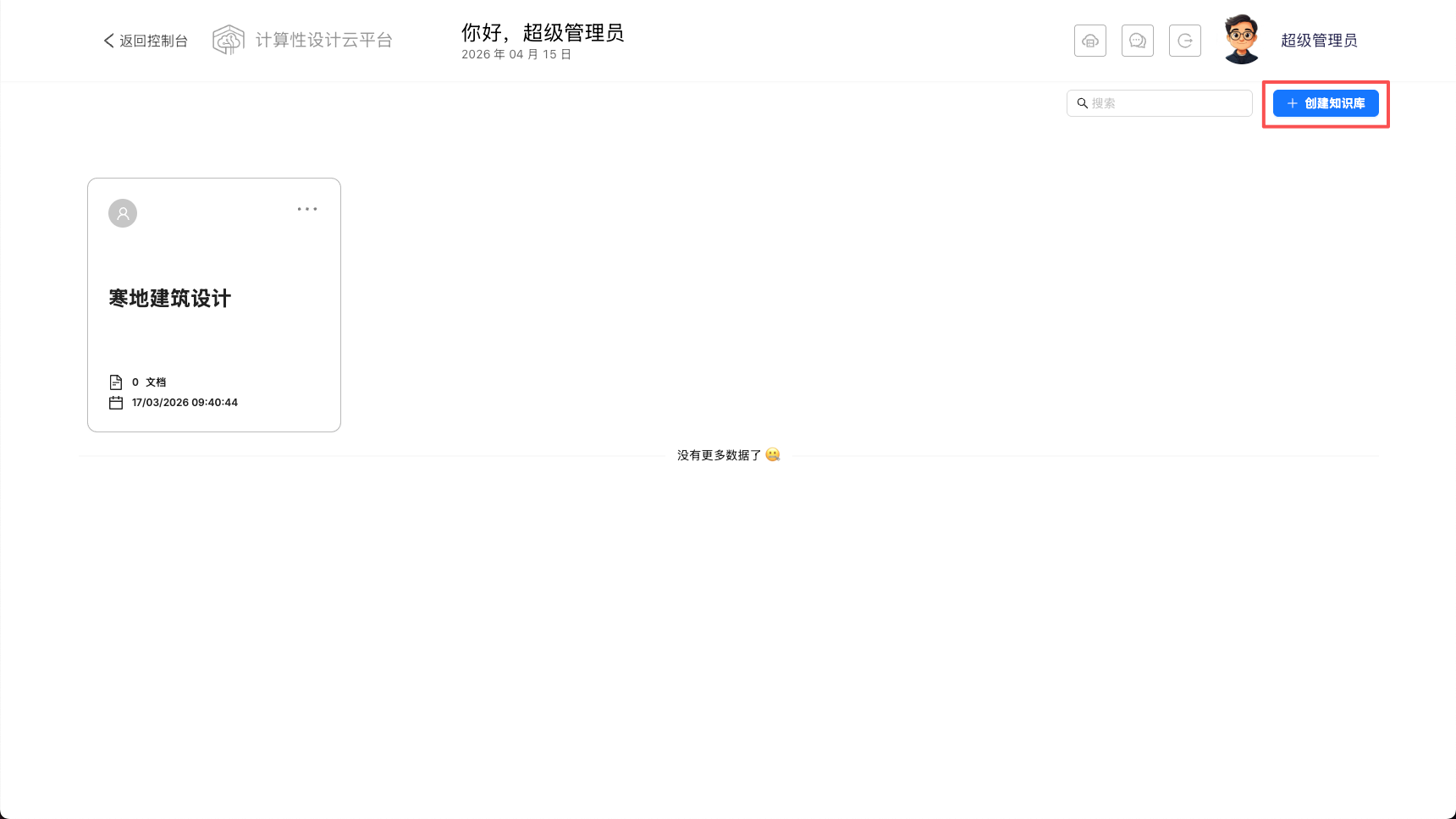
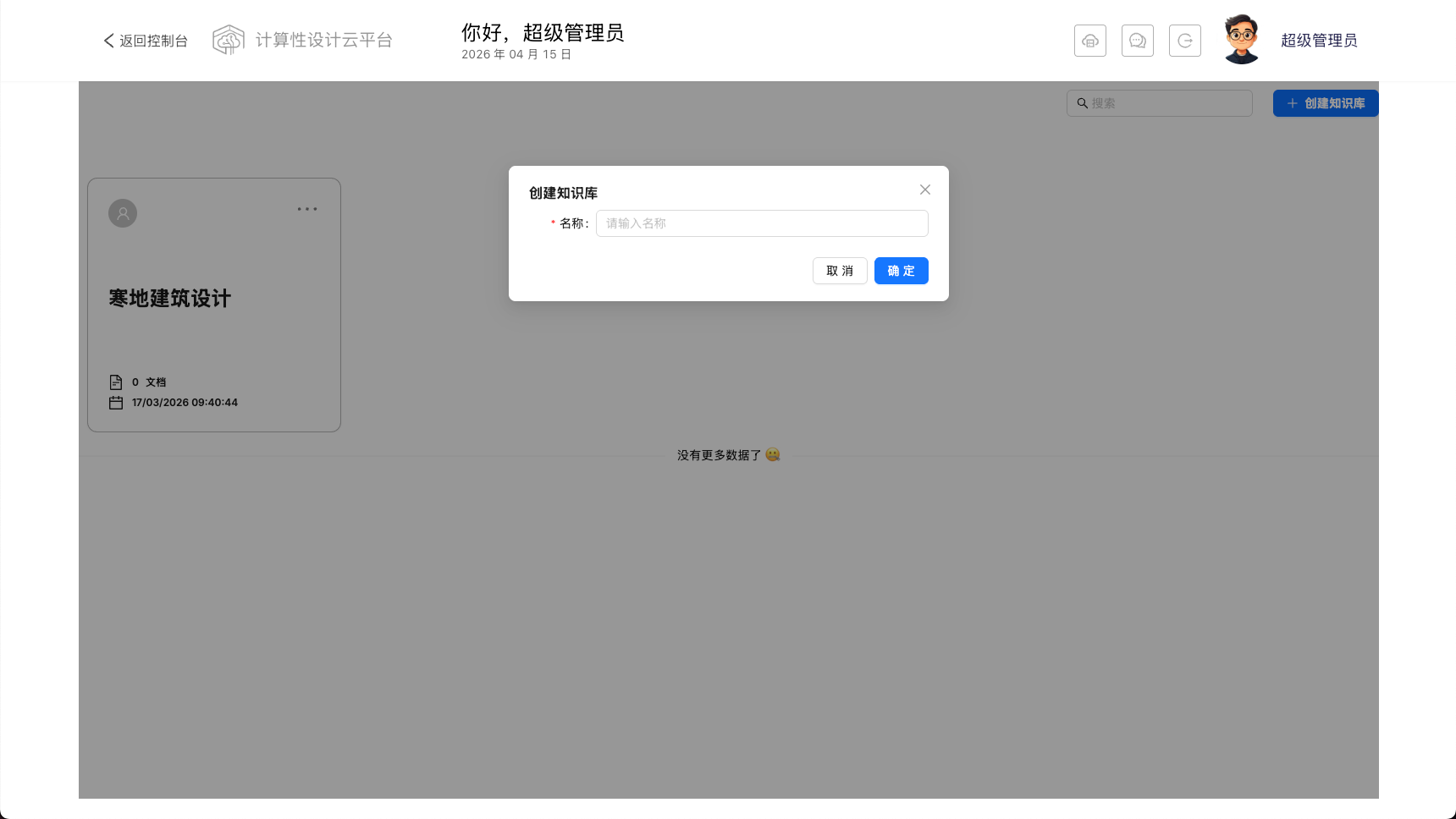
在此模块汇总,您可以点击界面右侧的创建知识库按钮进入创建知识库的页面。创建知识库时,您可以输入知识库名称,进入创建页面后根据需要进行相关配置。
知识库配置
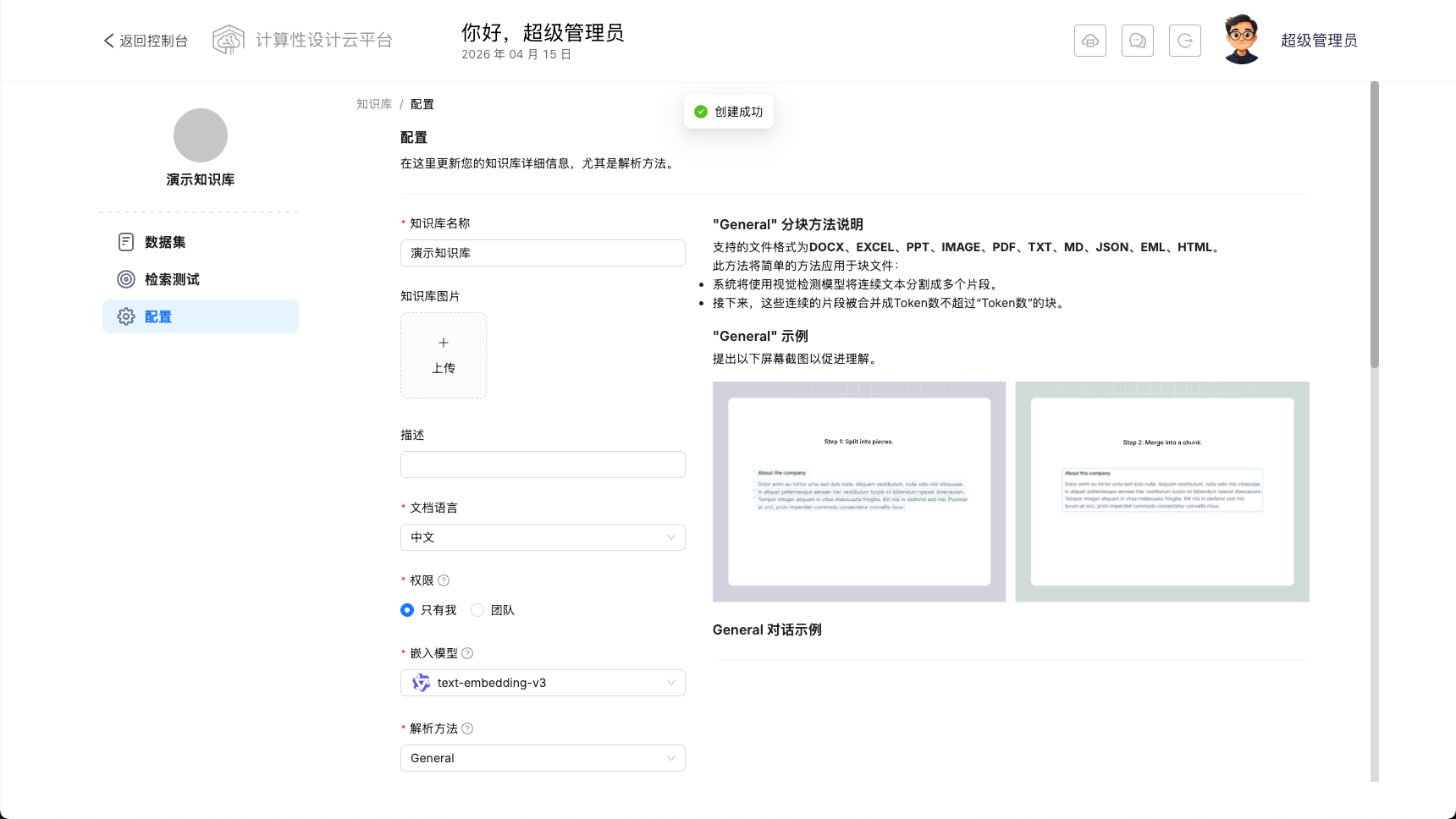
在此模块中,您可以对创建的知识库进行配置,配置项包括:
知识库图片:他是知识库的封面图片。
描述:您对此知识库的描述。
文档语言:这很重要,这表示模型将用什么语言语义解析模型分析文档。
权限: 此项表示知识库的权限,您可以选择私有或团队公开(暂时未开放团队能力)。
嵌入模型:向量解析模型,您可以选择云平台内置的多模型,当知识库存在文档 trunks 后,此项将不允许修改。
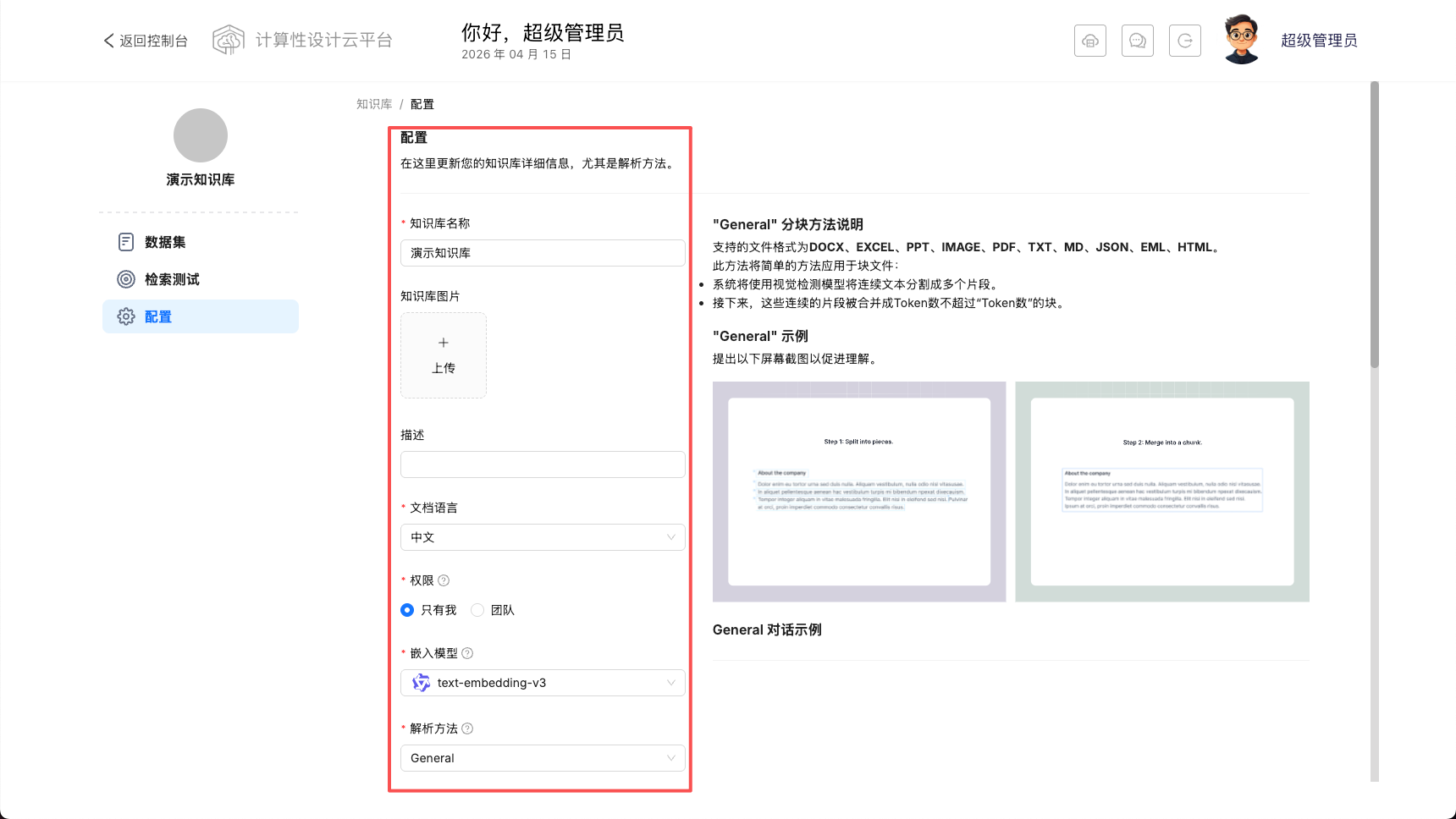
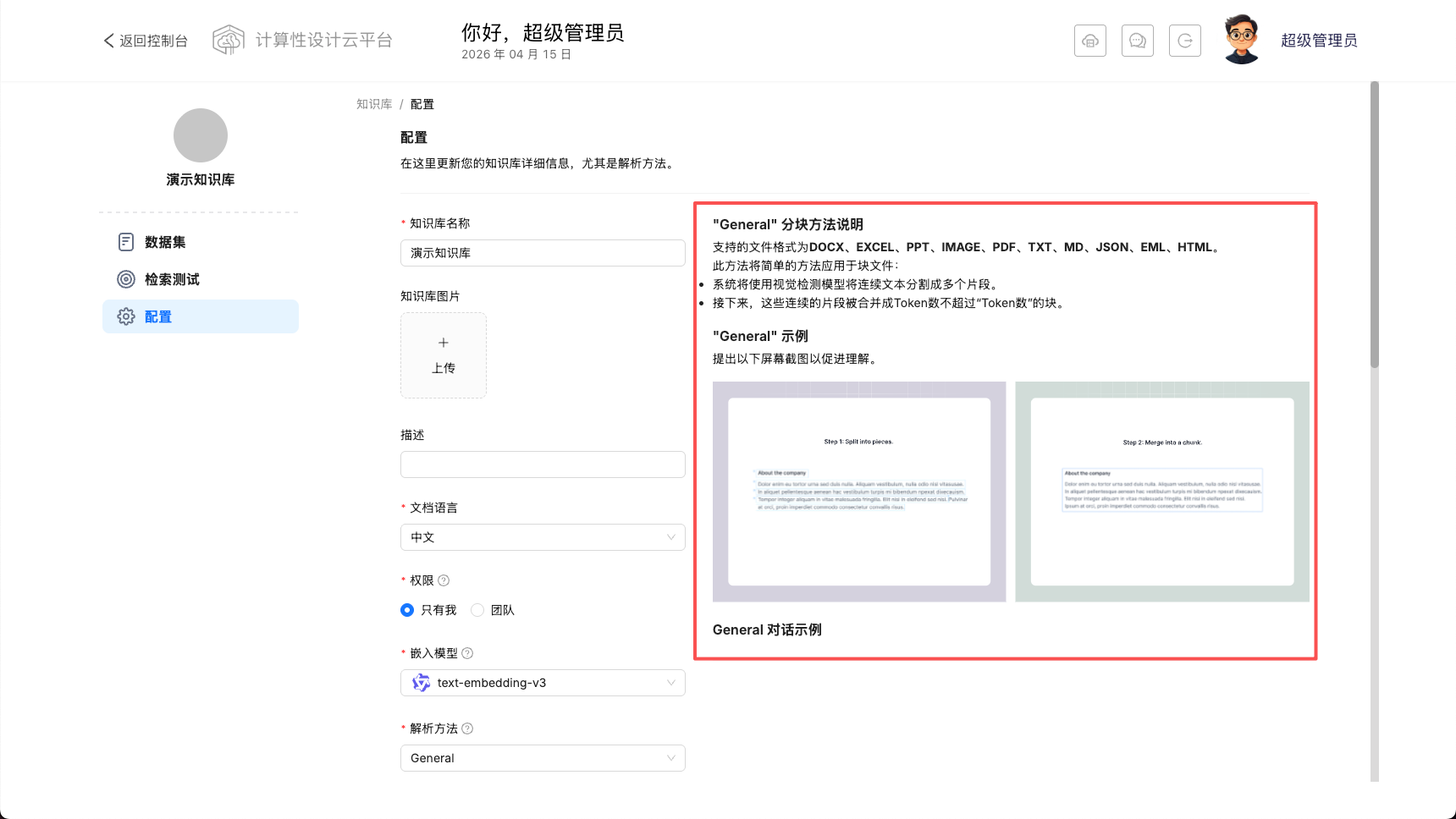
解析方法:此项表示模型将如何解析文档。您可以选择多种选项,每次切换右侧均将展示此解析方式说明。
页面排名:这用于提高相关性得分。所有检索到的块的相关性得分将加上此数字。 当您想首先搜索给定的知识库时,请设置比其他知识库更高的 pagerank 得分。
自动关键词:在查询此类关键词时,为每个块提取 N 个关键词以提高其排名得分。在“系统模型设置”中设置的 LLM 将消耗额外的 token。您可以在块列表中查看结果。
自动问题:在查询此类问题时,为每个块提取 N 个问题以提高其排名得分。在“系统模型设置”中设置的 LLM 将消耗额外的 token。您可以在块列表中查看结果。如果发生错误,此功能不会破坏整个分块过程,除了将空结果添加到原始块。
块 Token 数:它大致确定了一个块的Token数量。
分段标识符:支持多字符作为分隔符,多字符分隔符用
包裹。如配置成这样:##`;那么就会用换行,两个#以及分号先对文本进行分割,然后按照“ token number”大小进行拼装。布局识别和 OCR:使用视觉模型进行布局分析,以更好地识别文档结构,找到标题、文本块、图像和表格的位置。 如果没有此功能,则只能获取 PDF 的纯文本。
表格转 HTML:开启后电子表格会被解析为 HTML 表格,每张表格最多 256 行,否则会按行解析为键值对。
使用召回增强RAPTOR策略:请参考 https://huggingface.co/papers/2401.18059
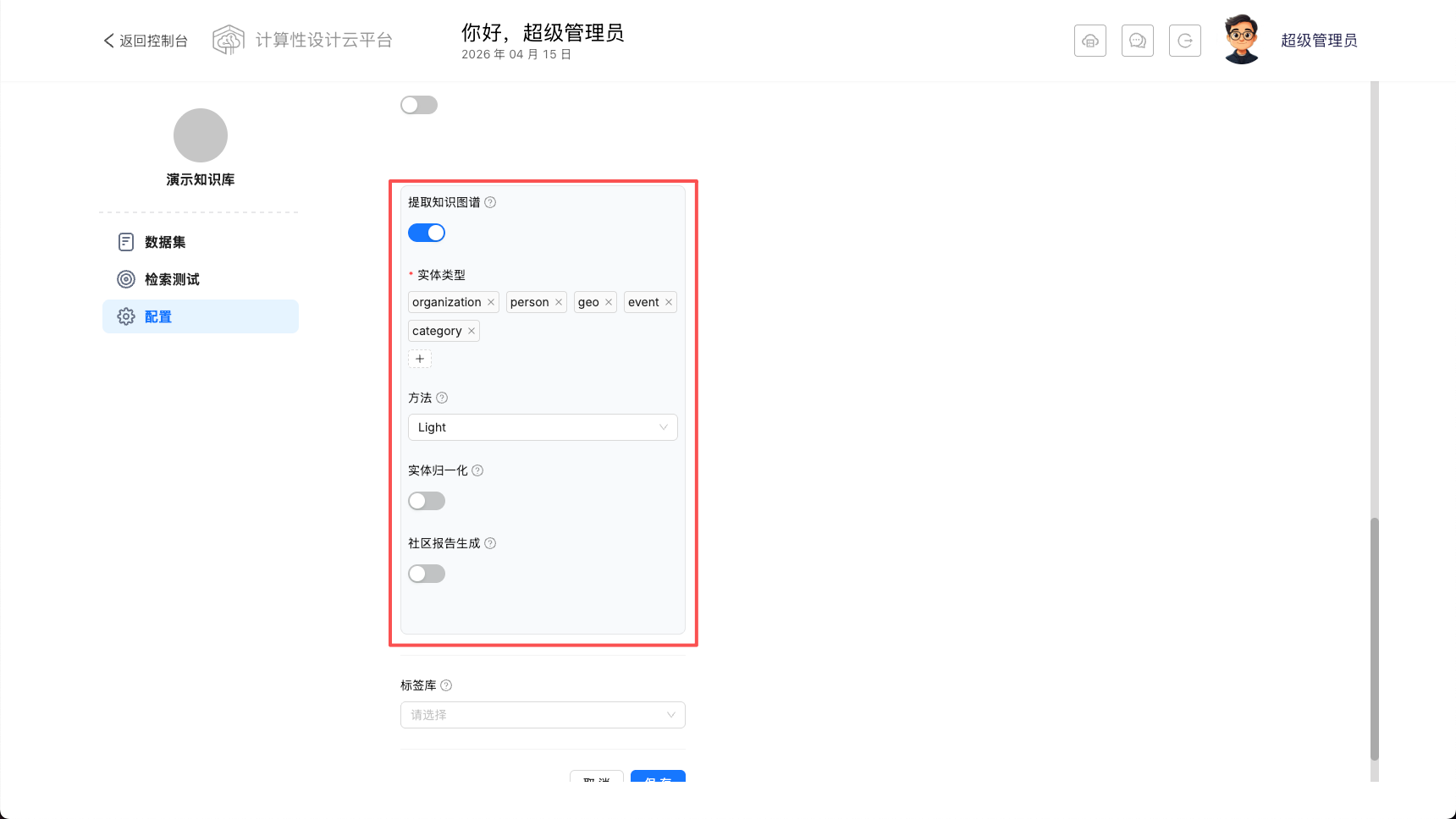
知识图谱
此配置将为您提取文档中的三元素进行知识图谱构建,云平台提供两种解析方式,分别为:
- Light:实体和关系提取提示来自 GitHub - HKUDS/LightRAG:“LightRAG:简单快速的检索增强生成”
- General:实体和关系提取提示来自 GitHub - microsoft/graphrag:基于图形的模块化检索增强生成 (RAG) 系统
您可以根据文档内容进行实体类型定义,这对多跳和复杂问题的推理大有帮助。
解析文档
配置好知识库后,您可以进入知识库,上传文档并开始解析。
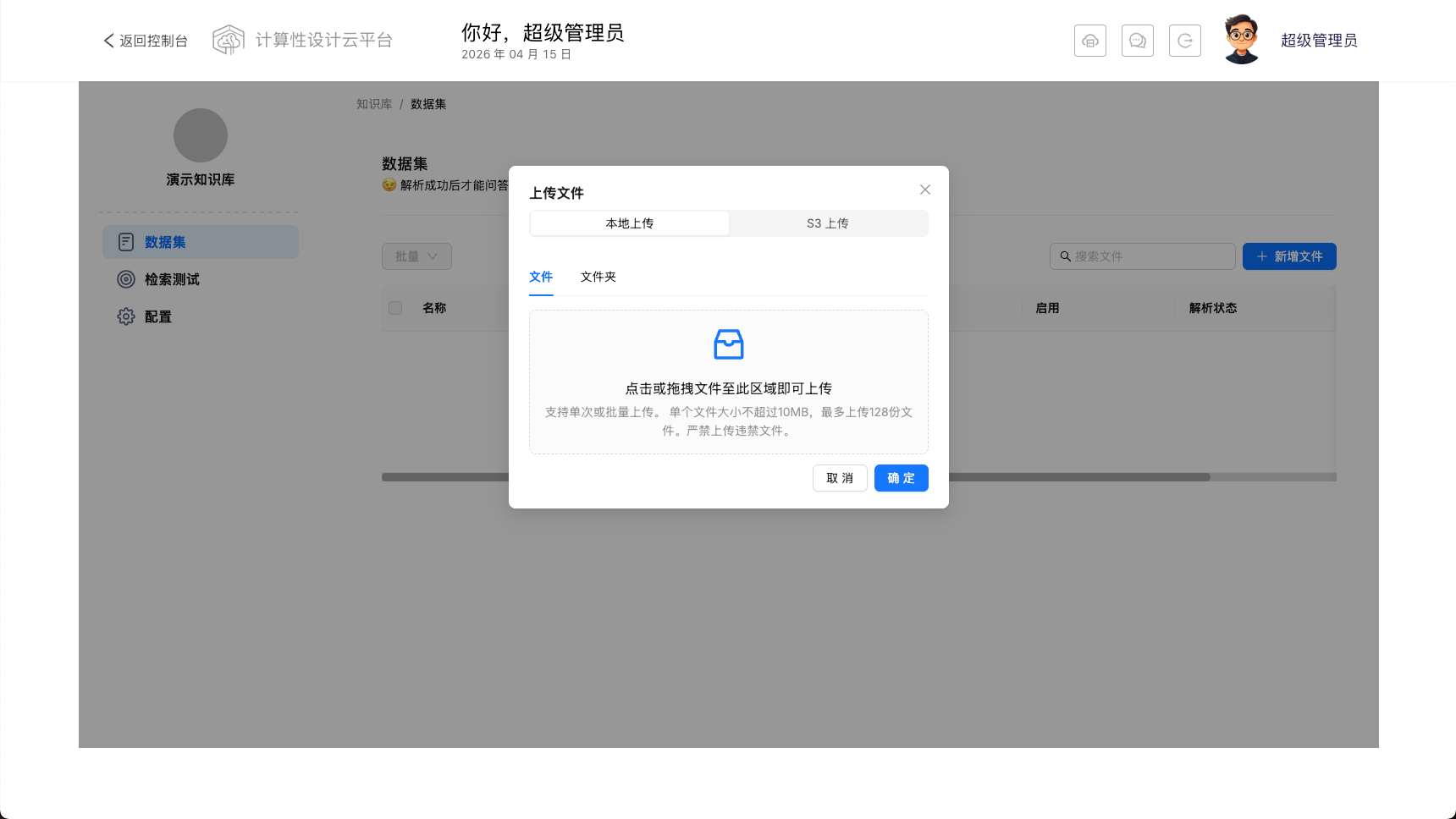
上传文件成功后,需要手动开始解析。开始解析后解析状态列变成解析进度,完后成变为成功。
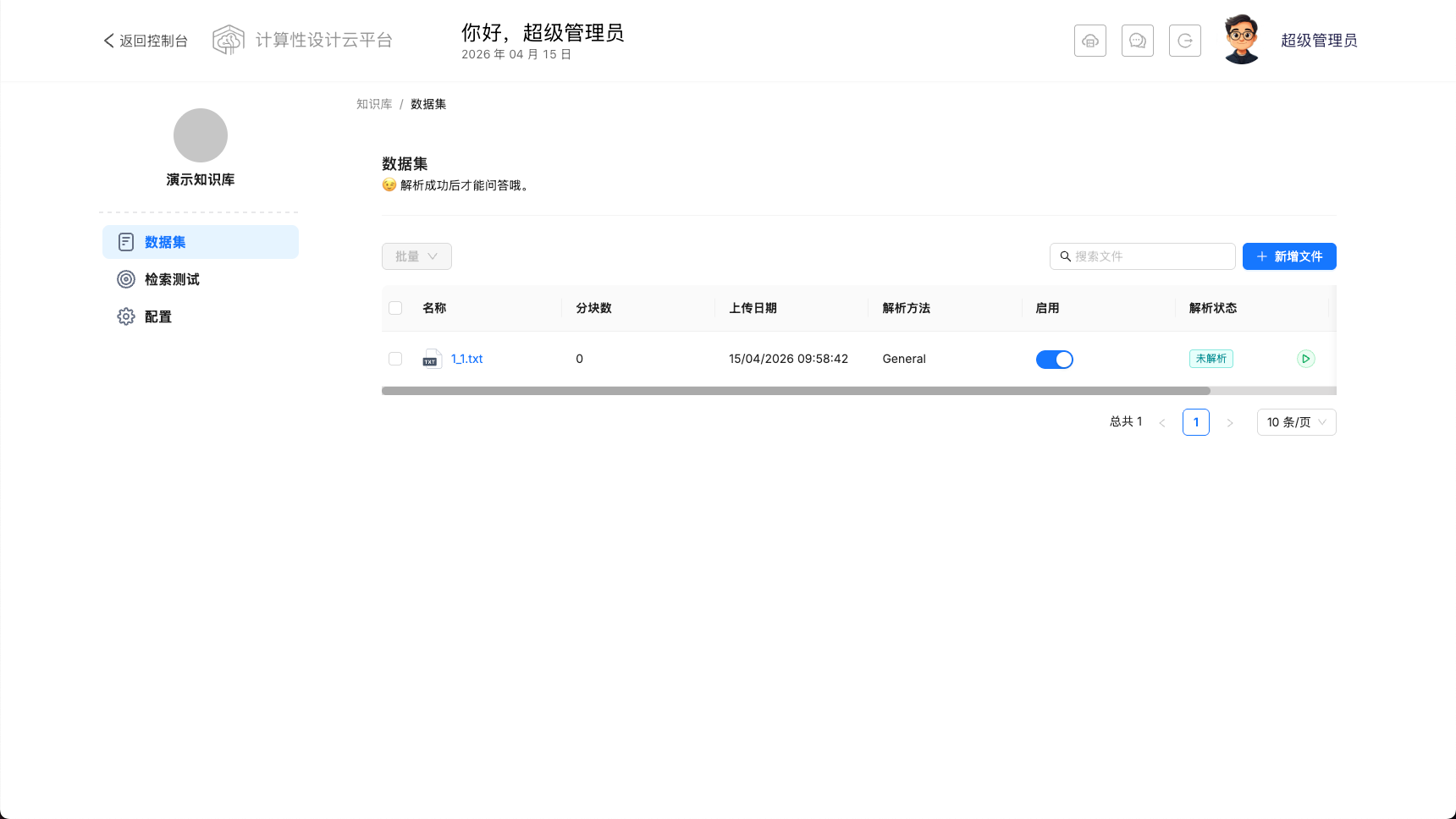
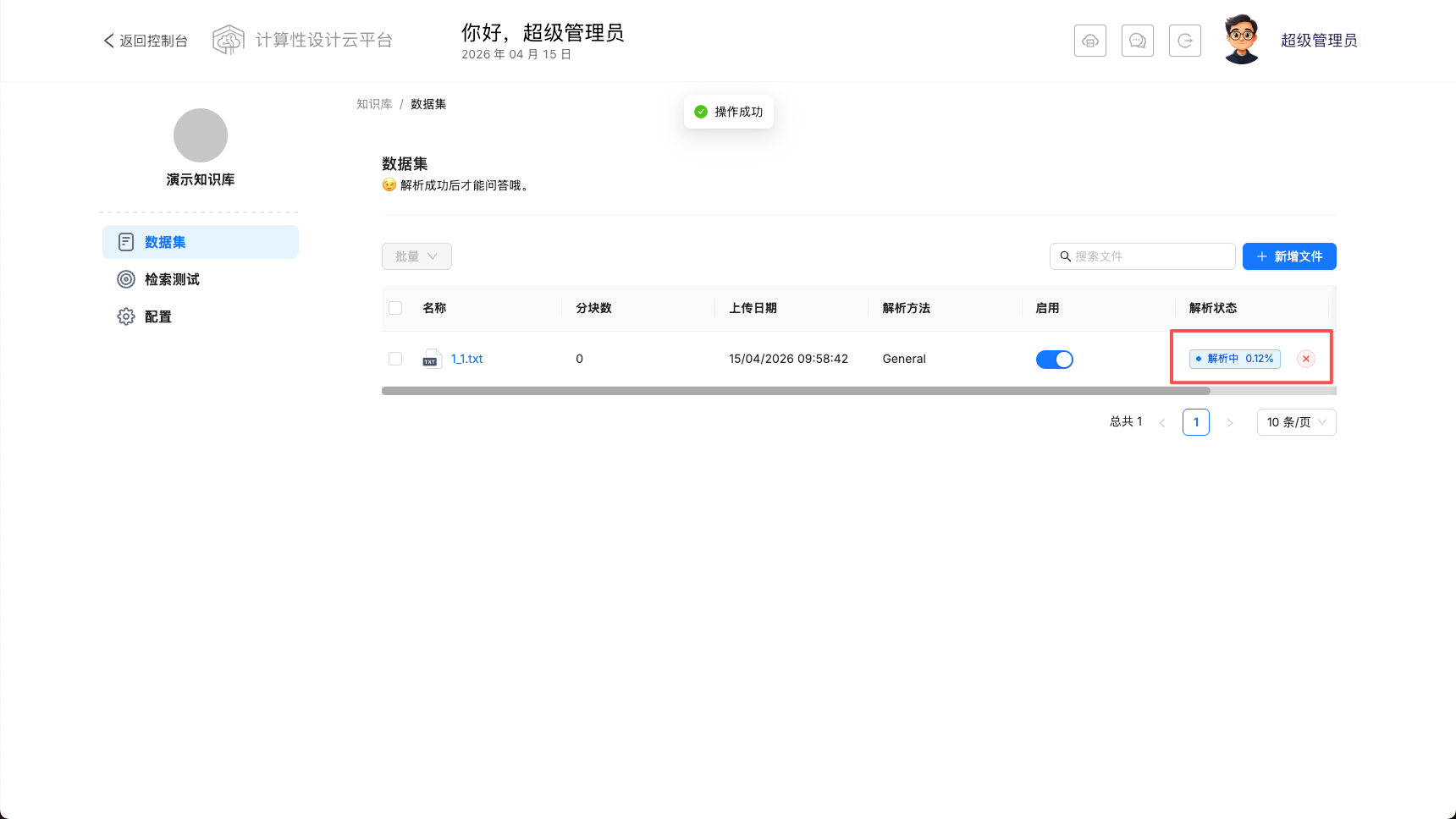
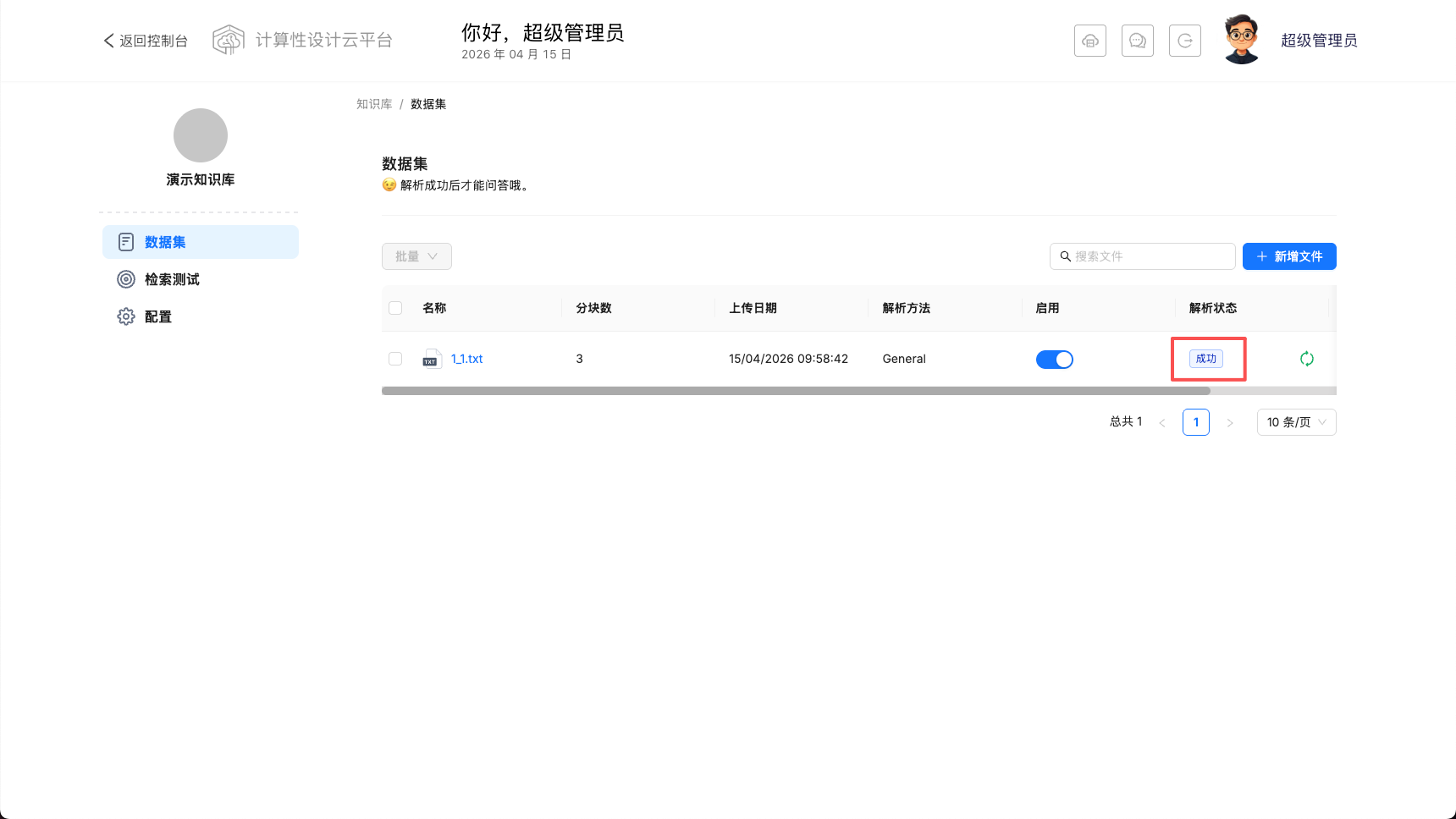
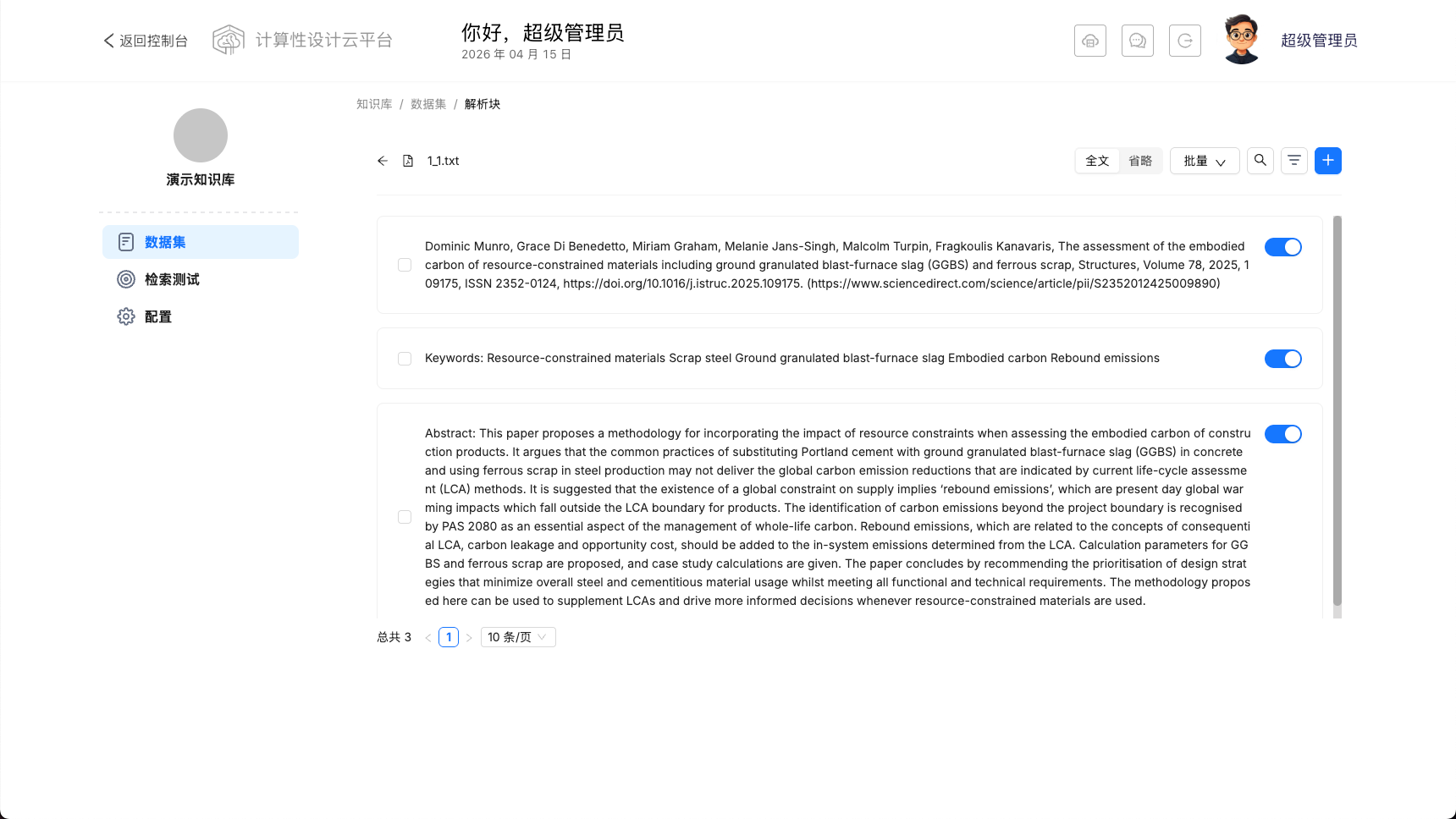
点击文件名称,可以查看文档解析trunks,可以手动启动或者关闭某些 trunks。